You can find the result of the project with the following link Techstack Analysis Report
As the digital landscape continues to evolve at a rapid pace, understanding the technologies that power websites has become increasingly crucial. From front-end frameworks to server-side languages, the array of tools and platforms available can be overwhelming for businesses and developers alike. In this data science project, we will do an analysis of website technologies to uncover insights that can inform strategic decision-making in the ever-changing world of web development. The benefits of such an analysis could be for example a database of possible business leads or having a basis for a data-driven hiring strategy.
The scope of this project ranges across the whole data science workflow, from raw data acquisition to reporting of the results. The list below highlights the individual milestones of the project, which we will discuss in detail later on:
- Compiling a reasonably sized dataset of website links with the corresponding industry branch and the technologies used to run the web presence
- Wrangling the data into an accessible format that can be used for further analysis
- Creation of an interactive web-based report featuring self-service analytics that can be used by decision makers
Gathering the dataset
If you ask data professionals about their favorite task, the answer will most certainly be scraping of unstructured web data, which can be considered the modern equivalent of working in a 19th century coal mine. Of course, web scraping was also the starting point for this project, with our first contact point being a well-known public database of Austrian companies. The idea here was to leverage their already existing categorization of websites into industry branches, which we can use for example to spot possible differences in technology choice. Maybe a web agency is specifically targeting retail businesses and want to exactly know their prevalent technology choices. By using the categories, we can add another layer of granularity to our dataset and answer such questions.
Gathering the data is done with a Python script that utilizes several libraries, including requests, BeautifulSoup, Wappalyzer, and fire. It uses the requests library to make an HTTP GET request and checks the status code of the response. If the status code is 200, indicating a successful request, the HTML content is returned. If the status code is 404, the script prints a message and skips the site. For status codes 400 and 500, the script continues the loop to retry the request. This method ensures that the script handles different scenarios when fetching web pages.
Overall, the script is designed to scrape multiple pages of each industry branch from the company database until a threshold of 1000 websites including technology stacks are gathered for each branch. The method iterates over the pagination, gets the URL for each company profile, and fetches the HTML content like discussed above. It then uses BeautifulSoup to parse the HTML and extract the actual website link for a company from the profile page. If a website link is found, the script uses the Wappalyzer library to analyze the technology stack of the website. The results are then written to a CSV file.
We always check if the actual website link returns a 200 status code so that we do not scrape broken links. Additionally, the fire library is employed to create a command-line interface for the script to allow running multiple instances of the script in tandem. Theoretically, we could use multiple threads, but having a dedicated terminal and status bar makes the whole process more manageable. To facilitate comprehension, I included a diagram of the scraping process, which can be seen here.
Wrangling and database creation
At the end of the data acquisition, we now have ten different CSV files (one for each branch), with each one containing 1000 websites and their technologies. The next steps of the project are concerned with bringing the raw data into a suitable format for the final analysis and visualization. First we load each of the ten CSV files and convert them into a single Pandas DataFrame which looks as following:
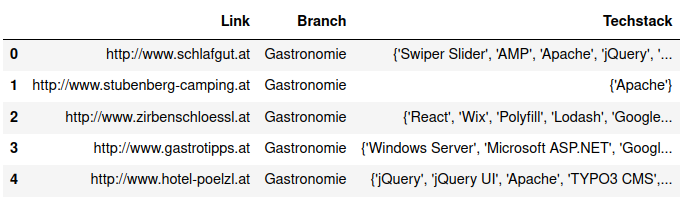
If we examine the “Techstack” column, we can see dictionaries containing the technologies. These dictionaries are thereby stored as strings. Now we have multiple possibilities to format our data, for example we could split our dictionaries and store each link, branch and technology combination as a distinct record in the DataFrame. Considering that we will also enrich our data with additional categories for the technologies and that a technology can have multiple categories, we quickly get a lot of redundant data to store. If we flatten out all possible combination, we blow up our DataFrame from 10000 to around 60000 records.
This would not be an issue for this small dataset, but if we want to incrementally add new data in the future, this would lead to issues at some point in time. To alleviate this problem, we will create a dedicated SQL database in third normal form to minimize the storage of redundant data. This database will then serve as the basis for our analysis and the web-based report. The ER-diagram below describes the schema that we will implement:
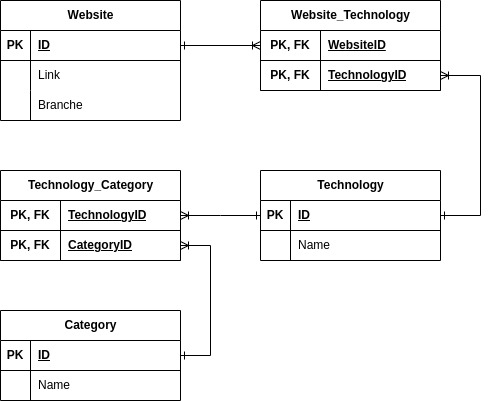
We create the database with the Sqlite3 library starting by creating a schema and following we fill the “Website”, “Technology” and “Category” table. The next step is also relatively straightforward, where we use loops and checks to fill up the so-called join tables named “Website_Technology” and “Technology_Category”. If you ask why the schema is set up in this form, consider the following example: A website has jQuery, WordPress and PHP in their technology stack. Regarding the categories of each technology, we have “JavaScript” library for jQuery, “Programming Language” for PHP and for WordPress we have two categories, namely “Blog” and “CMS” (Content Management System).
Now instead of creating an individual record for each possible combination, we just fill the “Website”, “Technology” and “Category” table with the respective entities and then create an entry for each relation in the join tables. So going back to our example, we would create three entries in the “Website_Technology” table, with all entries pointing at the website and each entry pointing at one of the technologies. Now we do the same for the “Technology_Category” table, and we can effectively reduce redundant data storage to a minimum. Additionally, we get the convenience of using SQL for our analysis in the next step
Deploying the Report
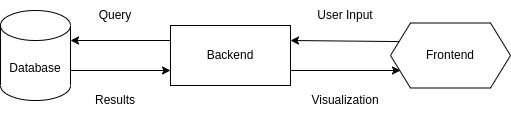
To follow suit with current state-of-the-art solutions for data visualization like Power BI or Tableau, we will create an interactive report with some basic self-service analytics. To do this, we use the Streamlit framework, which is optimized for fast development of data-apps with Python. The architecture of the web application is thereby relatively straightforward, because we basically connect standard front-end components like sliders, drop down menus and forms with SQL commands that interface with the database. With the additional integration of plotting capabilities in Streamlit, we can then build very neat data dashboards in a reasonable time. A quick overview of the architecture can be seen below:
Now there is not much left to say about the web app except that it can be viewed with the following link, so please take a look for yourself. -> Techstack Analysis Report
Conclusion
In this article, we looked at a project that encompassed the whole data science workflow, from gathering raw data to the creation of an interactive report that could be used by decision makers to guide their strategies. Such a project features a lot of different technologies and techniques that must be orchestrated to deliver a usable final result. Nonetheless, this usage of different tools for creative problem-solving, is probably the most exciting part of data science. As always, the code for this project can be found on GitHub in the following repository.