The internet is a nearly limitless source of information. This content is available to anyone with an internet connection and can be found in the form of text, audio, images, and videos. Because not every piece of information or type of format is important to each user, data retrieval can be a tedious task. Often, rather than being a convenience, this abundance of information might be a problem. To combat this issue and to satisfy the increasing need for data, processes that facilitate the retrieval of data need to be implemented. An example of such a process is web scraping which is used to create platforms where interesting data from different sources is aggregated to reduce information overload.
A good use case to employ web scraping technology is thereby the challenges of COVID-19-related data retrieval and aggregation. Thereby web scraping can be used to address the problem that different countries publish their data in various formats, channels, and intervals. This can make it difficult for researchers to fetch vital datasets for COVID-19-related research in an effective manner. Research concerning COVID-19 is an essential and ongoing effort starting just a few months since the virus began spreading around the globe. Thereby researchers are making great efforts to understand the virus’s characteristics, the causes of its effects, and possible precautionary care.
Not only can academic research benefit from facilitated access to data, but also for the general public, this aggregated data can be helpful. But in contrast to academics, normal people are used to seeing more easily interpretable figures and graphs that illustrate the development of data. Thereby different types of data visualizations like how COVID-19 affects specific geographic locations or age groups and the visualization of key metrics over time can aid in the understanding of the virus characteristics.
As has been explained, individuals often spend a lot of time and effort trying to find the most recent information from multiple sources. This is inconvenient, and as a result, we need a system capable of providing targeted, aggregated, and up-to-date information for important COVID-19-related metrics, which are normally scattered around various websites. The developed web scraping application, which is specialized in aggregating data from the DACH region, allows users to access a visualization of three key metrics, namely the total infections, total deaths, and the seven-day incidence.
This concise overview of three of the most important metrics regarding COVID-19 aims to reduce information overload while still providing a good picture of the current situation in the three countries of the DACH region. Thereby the data is scraped from three selected sources at a daily interval. To facilitate COVID-19-related research, the data which has been scraped since deploying the application can be downloaded in HDF5 format and further analyzed.
A Primer on Web Scraping
Web scraping is a data mining technique used to extract unstructured information from various online resources, format the data so it can be saved and analyzed in a database, and then convert the obtained data into a structure that is more valuable for the user. A well-organized web scraper routinely scans targeted data sources and gathers valuable information into an actionable database. Web scraping has many forms, including copying and pasting, HTML parsing, or text grabbing.
The retrieval of the data can roughly be divided into two steps which are executed sequentially. First, a connection to the requested website is established, and following the content of the website is extracted. In essence, the web scraper copies the classical behavior of a user when surfing the web, searching for and downloading information, only that the actions are automated. To date, a variety of tools and techniques for web scraping are in existence, with the two most popular being parsing the HTML of a website or simulating a complete browser. The latter of the methods can be used if dynamically generated websites that rely on JavaScript being executed by the browser prohibit the first method.
The internet’s popularity was the catalyst of the need to scrape online resources. The first famous scrapers were created to search for information by search engine developers. These types of scrapers go through most of the internet, analyze every web page, extract information from it, and build a searchable index. The use of web scraping has grown in a variety of diverse fields, including e-commerce, content creation for the web, real estate, tourism, finance, and law.
Literature Review
Before creating the web application, a literature review was conducted to get an overview of possible use cases and research applications of web scraping technology. For example, public health and epidemiology investigations frequently involve web scraping. Researchers can possibly identify risks and food dangers and also anticipate possible future epidemics by scraping and analyzing textual data stored on the world wide web.
An example would be that Pollett and co used a web scraping approach to gather unorganized online news data to enable them to identify outbreaks and epidemics of vector-borne diseases. Another example would be Walid and associates, who gathered Twitter data over two years to develop a cancer detection and prediction algorithm. Thereby the team combined the Twitter data and sentiment analysis with natural language processing. In 2015, Majumder et al. used web-scraped health information from HealthMap in conjunction with Google Trend time series information to determine the projected size of a Zika virus pandemic.
As already mentioned, web scraping is also being used to identify food-related dangers. Ihm and coworkers developed a method to defuse and manage food emergencies in Korea by scraping social media and news for events involving food hazards. Another example would be the usage of web scraping for gathering Yelp reviews to discover cases of food-related illnesses which were not reported. This was done by the New York City Department of Health and Mental Hygiene between 2013 and 2014.
Similar studies have also been conducted in regard to COVID-19-related issues. Lan et al. sought to assess the discourse on policies to deal with the coronavirus pandemic through official press articles, social networks, and media outlets. Xu and colleagues scraped Weibo postings from Wuhan to assess public sentiment, understanding, and attitudes in the lead-up to the early stages of the COVID-19 pandemic. Future policy decisions and future epidemic responses may be guided by their findings.
Project Methodology
One significant barrier is the lack of a standardized, regularly updated, and high-quality data source for information on COVID-19 cases in the DACH region. This is due to the fact that the different nations distribute information on unique platforms, institutions, and time cycles that negatively affect researchers’ access to crucial coronavirus datasets for medical analyses at satisfactory resolutions.
To overcome this problem, the developed web application is set up to look for statistical information on COVID-19 using web scraping procedures. Three websites, namely www.rki.de, coron-avirus.datenfakten.at, and www.corona-in-zahlen.de, form the basis for the collection and aggregation of COVID-19 key metrics. The information about the current development is thereby scraped daily and saved inside a relational database. Following, we will discuss the inner workings of the proposed application.
The application can really be split into two parts according to their functionality, which is the front-end for display and download of the gathered data and the actual web scraping. The whole application is thereby set up as a web application based on the Django library, a well-known Python library for web applications.
Data Scraping Logic
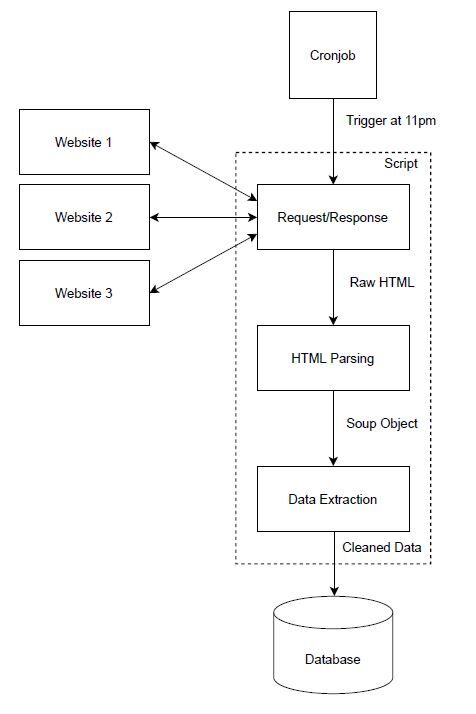
The task of gathering the COVID-19 data from the three aforementioned websites is done by a single Python script which is implemented as a Django command and executed by a cronjob which is registered on the server hosting the web application. For scraping, the application leverages the Requests and BeautifulSoup4 library, which will be reviewed in detail later on.
As already mentioned, the web scraping process is triggered by the cronjob at the scheduled time of eleven PM. The script works by sending an HTTP request to retrieve the raw HTML, which is then parsed with BeautifulSoup4. The parsing process yields a Soup object which is then examined to extract the needed information, which in our case are total infections, total deaths, and the 7-day incidence for each website, respectively. The resulting 9 data points, three for each county, are then saved in the relational database, which is implemented with the SQLite library. The following image illustrates the process.
After discussing the general process of the scraping logic, we will take a look into the two Python libraries used for web scraping, namely Requests and BeautifulSoup4.
Requests
Requests is a simple, tried-and-true HTTP library for the Python programming language that allows sending HTTP requests very easily. The Requests library is built upon Python’s urllib3, but it lets you manage the vast majority of HTTP use cases with code that is short, pretty, and easy to use. To get a web page, we have to call the get method of the library and issue the website URL as a parameter. The response of the server is then contained in the response object. When working on an application, it’s often required to deal with raw, JSON, or binary response. Therefore it is needed to decode the response of a web server, which is also handled by the Requests library.
BeautifulSoup4
Beautiful Soup is a Python library for extracting data from HTML and XML files. The library formats and organizes the data from the web by fixing bad HTML and giving us easily traversable Python objects corresponding to XML structures. The most widely used object in the BeautifulSoup library is the BeautifulSoup object which takes the HTML content of a webpage and a parser as arguments. In our case, the HTML content is the response object and specifically the raw string format of the response object and the Python built-in html.parser, which are both passed as arguments.
Data Visualization and Provision
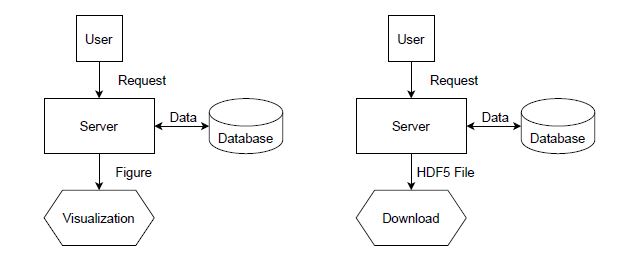
After looking into the web scraping part of the application, we will now discuss the second part of the application, which is concerned with the visualization of the gathered data and the provision of the data as a HDF5 file. The front end of the web application is implemented as a single page which is served by a Django view function. Thereby the function works by gathering all data from the database inside a dictionary which is then used to generate a figure. The figure is then sent to the browser for rendering. Like the data visualization, the provision of a HDF5 file works on a similar basis. The process starts by clicking the download button on the index page of the web application. This triggers the registered view, which first queries all entries in the database, but instead of creating a figure for visualization, the web application then creates a HDF5 file and serves it as a file to the user.
HDF5
To make the gathered dataset accessible for researchers and to facilitate analysis, the format chosen for data provision is the HDF5 file format. HDF5 is used for storing and exchanging data. It supports all types of data, is designed for flexible data input and output, and can store large volumes of complex information. The HDF5 data model is composed of three elements which are datasets, groups, and attributes. A user can use these elements to construct particular application formats that organize data in a way that suits the problem domain. HDF5 also handles all issues related to cross-platform storage, so sharing data with others is a straightforward matter. The actual HDF5 library is implemented in C, and both of the most popular Python interfaces, h5py, and PyTables, are designed as a wrapper around the C library.
Pandas HDF5 Capabilities
Pandas is a Python library for data analysis with several data structures and functions designed to make working with structured or tabular data more intuitive. Additionally and more relevant for this project, the Pandas library contains functionality for reading and writing HDF5 files, which is implemented with the PyTables library. Thereby a Pandas DataFrame, which is the library table-like data structure, can easily be converted into the datasets, groups, and attributes that make up a HDF5 file.
Discussion of the Results
Users can access the most recent COVID-19-related information from three websites covering the DACH region with the help of the developed web application. Since the data is scattered around different websites and often buried under a lot of other information, this application provides added value to the original data. People typically do not have the time to research many websites to gather data or information since they are too busy with everyday activities, which makes a central overview of key metrics very convenient.
Given that the application is processing data that is not originally our own, we must also examine the legal concerns which are tied to a web scraping application. Scraping data for personal use poses practically no problem. However, if the acquired data is published again, then it is crucial to consider which type of data is processed. Internationally recognized court trials have helped define what’s acceptable for scraping websites. These trials indicate that if copied data are facts, the data can be repurposed. However, data that is original, for example, ideas, news, and opinions, cannot be used because many times the information is copyrighted. Given that the application scrapes factual information, we can establish a case for the scraping, aggregation, and republishing of this data.
Comparison with the Literature
To compare the proposed methodology of this project, a review of similar studies was conducted. For example, in 2021, Lan and colleagues created an accessible toolkit that can automatically scan, scrape, collect, unify, and save the data from COVID-19 data sources from different countries across the world. They also used Python as a programming language and well-known packages like Beau-tifulSoup, Selenium, and Pandas for the collection and processing of the data. In a single run, the application will gather information from all over the world. The information is then consolidated in a single database for sharing after post-processing and data cleansing. The COVID-Scraper also provides a visualization feature to make the whole data available for viewing as a web service. Additionally, the data can be downloaded as a PDF. The tool developed in this study also features the ability to process PDFs, images, and dynamically generated websites.
Another interesting study used Python with libraries like Scrapy, which is focused on the development of web crawlers, to scrape big scholarly databases like PubMed and arXiv. The process involved first searching for COVID-19-related papers in a variety of databases and then collecting the metadata of the search results with web scraping techniques. The acquired metadata was then processed with the Pandas library, which included cleaning and normalizing the data, and then merged into a single dataset in the form of a CSV file. The resulting dataset features over 40,000 records of metadata related to COVID-19 research. The intended usage of the aggregated dataset is to detect possible trends, gaps, or other interesting facts about COVID-19 research in general. The study also used version control systems for the Python code.
By comparing the developed web application with other approaches from the literature, we can establish a case for using the proposed techniques and technology but also derive ideas for improving the application further. For example, a limitation of the application in its current form is that dynamically generated websites cannot be scraped because a library like Selenium is needed. Selenium thereby simulates a browser that can execute JavaScript that gathers information from the server by asynchronous requests. This reveals data that stays hidden when using libraries like Requests. Additionally, the application can be further improved by allowing for file-based scraping. Given that a lot of data sources publish their information as PDFs or CSV files, this can further broaden the range of data that can be processed by the application.
Conclusion
The ever-increasing amount of information available on the internet and the scale of that information’s development over time leads to search queries that produce vague and unspecific results. However, by making use of information extraction methods, we can diminish the reach of this issue and focus useful information on a single platform. Billions of people worldwide have been affected by the outbreak of the coronavirus. Organizations, governments, and researchers are working diligently to research the issue of COVID-19 and achieve the goal of returning civilians to their natural way of living as soon as possible.
Researchers around the world have used comprehensive COVID-19 records to provide information that contributed to the progress of COVID-19 research. In order to efficiently obtain, compile, preserve, and exchange data that is open to the public, we have implemented an online application that scrapes selected COVID-19 metrics from the aforementioned three websites. It is useful for residents of the DACH area to witness the progression of COVID-19 over time. Under the proposed parameters, the CoronaScraper is a highly adaptable and automated tool that facilitates research and provides targeted information to the public. As always the code is available on GitHub.
Reference
Al Walid, M. H. (2019). Data analysis and visualization of continental cancer situation by twitter scraping. International Journal of Modern Education and Computer Science, 11(7), 23–31.
Chandra, R. V. (2015). Python requests essentials. Birmingham: Packt Publishing. Collete, A. (2013). Python and hdf5: Unlocking scientific data. Sebastopol: O’Reilly.
Comba, J. L. D. (2020). Data visualization for the understanding of covid-19. Computing in Science & Engineering, 22(6), 81–86.
Deepak, K. M., & Lisha, S. (2016). A dive into web scraper world. 2016 3rd International Conference on Computing for Sustainable Global Development , 689–693.
Dongthi, T., Nguyen, Kieuthi, Chung, T., & Dong Thi Thao, N. (2020). New trends in technology application in education and capacities of universities lecturers during the covid-19 pandemic. nter-national Journal of Mechanical and Production Engineering Research and Development (10), 1709–1714.
Hajba, G. L. (2018). Website scraping with python: Using beautifulsoup and scrapy. Berkeley: Apress L. P.
Harris, J. K., Mansour, R., Choucair, B., Olson, J., Nissen, C., & Bhatt, J. (2014). Health department use of social media to identify foodborne illness - chicago, illinois, 2013-2014. Morbidity and Mortality Weekly Report , 63(32), 681–685.
Ihm, H., Jang, K., Lee, K., Jang, G., Seo, M.-G., Han, K., & Myaeng, S.-H. (2017). Multi-source food hazard event extraction for public health. In 2017 ieee international conference on big data and smart computing (pp. 414–417).
Kenneth, R. (2022). Requests: Http for humans. Retrieved from https://requests.readthedocs.io/en/latest/
La, V.-P., Pham, T.-H., Ho, M.-T., Nguyen, M.-H., P. Nguyen, K.-L., Vuong, T.-T., . . . Vuong, Q.-H. (2020). Policy response, social media and science journalism for the sustainability of the public health system amid the covid-19 outbreak: The vietnam lessons. Sustainability , 12(7), 2931.
Lan, H., Sha, D., Malarvizhi, A. S., Liu, Y., Li, Y., Meister, N., . . . Yang, C. P. (2021). Covid-scraper: An open-source toolset for automatically scraping and processing global multi scale spatiotemporal covid-19 records. Ieee Access, 9, 84783–84798.
Lawson, R. (2015). Web scraping with python: Scrape data from any website with the power of python. Birmingham: Packt Publishing.
Majumder, M. S., Santillana, M., Mekaru, S. R., McGinnis, D. P., Khan, K., & Brownstein, J. S. (2016). Utilizing nontraditional data sources for near real-time estimation of transmission dynamics during the 2015-2016 colombian zika virus disease outbreak. JMIR public health and surveillance, 2(1), e30.
McKinney, W. (2018). Python for data analysis: Data wrangling with pandas, numpy, and ipython (2nd ed.). Sebastopol: O’Reilly.
Mitchell, R. (2015). Web scraping with python: Collecting data from the modern web (1st ed.). Sebastopol: O’Reilly.
Pandas. (2022). Input/output — pandas documentation. Retrieved from https://pandas.pydata.org/pandas-docs/dev/reference/io.html#hdfstore-pytables-hdf5
Pollett, S., Althouse, B. M., Forshey, B., Rutherford, G. W., & Jarman, R. G. (2017). Internet-based biosurveillance methods for vector-borne diseases: Are they novel public health tools or just novelties? PLoS Neglected Tropical Diseases, 11(11), e0005871.
Richardson, L. (2021). Beautiful soup documentation. Retrieved from https://beautiful-soup-4.readthedocs.io/en/latest/S. D. S, S. (2015). A comparative study on web scraping. In Proceedings of 8th international research conference.
Santos, B. S., Silva, I., Da Ribeiro-Dantas, M. C., Alves, G., Endo, P. T., & Lima, L. (2020). Covid-19: A scholarly production dataset report for research analysis. Data in brief , 32, 106178.
Shakra, M., Rabia, Z., Sharaz, A., & Sohail Masood, B. (2019). Exploiting filtering approach with web scrapping for smart online shopping : Penny wise: A wise tool for online shopping. 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies, 1–5.
The HDF Group. (2022). Hdf5. Retrieved from https://portal.hdfgroup.org/display/HDF5/ HDF5 The Octoparse Team. (2022). 9 industries benefiting from web scraper octoparse. Retrieved from https://www.octoparse.com/blog/9-industries-benefit-from-web-scraper-octoparse
Upadhyay, S., Pant, V., Bhasin, S., & Pattanshetti, M. K. (2017). Articulating the construction of a web scraper for massive data extraction. In Proceedings of the 2017 second ieee international conference on electrical, computer and communication technologies (pp. 1–4).
vanden Broucke, S. (2018). Practical web scraping for data science: Best practices and examples with python. New York: Apress.
Xu, Q., Shen, Z., Shah, N., Cuomo, R., Cai, M., Brown, M., . . . Mackey, T. (2020). Characterizing weibo social media posts from wuhan, china during the early stages of the covid-19 pandemic: Qualitative content analysis. JMIR public health and surveillance, 6(4), e24125.