
In today’s rapidly evolving world of data science, staying ahead of the curve and understanding market demand is crucial. Aspiring data scientists often wonder which skills to focus on developing and what kind of compensation they can expect. In a recent project, I scraped public job postings in Austria to uncover the most sought-after skills and explore salary ranges for data science-related positions. Join me as we unveil intriguing insights into Austria’s data science job market.
Scraping Data
The first step of the project was to collect a dataset of job postings from an online resource, in this case the online job board Karriere.at. The goal was to capture valuable information like required skills and associated salaries, allowing us to gain actionable insights. To start the data collection, I first searched for the term “data science” on the job board, which yielded 310 results at the time I started the project.

The next step was to simply copy the HTML source code of the website, which contained all the links to the individual job postings. By leveraging the Requests and BeautifoulSoup Python libraries, I first extracted the links, then scraped the HTML and extracted the text for each listing. This resulted in 310 text files containing the job description in an unstructured format.
Extracting Skills and Salaries
To extract the skills and salaries from the scraped job postings, I employed OpenAI’s Chat Completions API with the GPT-3.5-Turbo model, or for short, ChatGPT. The large-language model allows us to effectively extract the information of interest from the unstructured data via a well-crafted prompt. The skill and salary extraction is thereby split into two tasks, so the first processing of the postings only extracts the skills, and the second run extracts the salaries. The image below shows the unstructured text data and the extracted skills and salary plus salary period, which will be used for further analysis.

Data Cleaning and DataFrame creation
Once the necessary information was collected, I transformed it into a structured format suitable for comprehensive analysis. This involved organizing the extracted skills and their associated salaries into a clean DataFrame, ready for deeper exploration. To clean up the skills, the first step was to tokenize the comma-separated list returned by the Chat Completions API. Following was lowercasing, removal of spaces, hyphens and special characters, and also the removal of company names like Microsoft and Google. All these steps help to basically reduce the noise in the data that results from different wordings. For example, by looking into the data, I saw a lot of different wordings for Azure, namely MS Azure, Microsoft Azure and microsoft azure which all denote the same skill. Finally, employing all these cleaning steps resulted in a list of 785 different skills, which were consequently used to create a one-hot encoded DataFrame for further analysis.
Analyzing Sought-After Skills
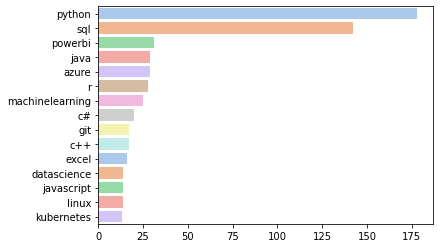
With our properly structured dataset at hand, we can now delve into analyzing the most sought-after skills in Austria’s data science job market. This is done by simply counting the rows that contain the value “true” for the respective skill and sorting in descending order. If we look at the bar plot below, we can identify key skills that repeatedly cropped up across numerous job postings.
Revealing Salary Ranges
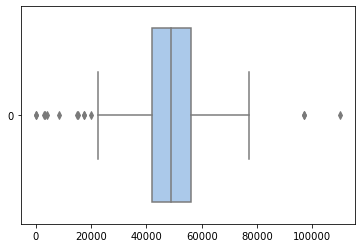
In addition to uncovering the essential skills sought by employers, we also examine the salary ranges offered for data-related roles in Austria. By creating a box plot of the provided salaries, we can see the distribution of salaries over the different data-related roles. Here we get a mean and median of around 49,000 euros.
Insights and Limitations
Throughout the analysis, several noteworthy findings emerged. The first finding is that Python and SQL are by far the most sought-after skills, with around 50 percent of the jobs demanding these two skills. Looking further at place three, we can see that there is a demand for Power BI, which is a business intelligence product offered by Microsoft. Following, we have a mixture of several programming languages and technologies. If we look at the salaries, we can see that we have several outliers, especially towards the lower end, which are probably a result of an error from the salary extraction pipeline or postings that give hourly wages that are not accounted for. The same is true for the skill extraction, which is comprehensive but not perfect. This could be accounted for by fine-tuning a model for this task. Nonetheless, given the zero-shot prompt approach, I am very happy with the results, which coincide with common knowledge about the field of data science and related job roles.
Conclusion
Our data analysis project sheds light on the current landscape of Austria’s data science job market by uncovering sought-after skills and highlighting salary ranges. According to our analysis, a well-rounded approach to acquiring skills would first require a solid understanding of Python and its usage in data-related scenarios. The following is a study of SQL and the concept of relational databases. A business intelligence solution like Power BI further adds to the skill set, which is now more focused on data analytics than data science. In general, the results of our analysis state a higher demand for data analytics than data science.
Alternatively, or to further expand one’s skill set, the usage of the Microsoft Azure platform for data-related workloads would be a great addition. Programming languages like Java, JavaScript, C#, or C++ and version control with GIT are more in the realm of software engineering. Armed with this knowledge, aspiring data scientists can effectively prioritize their skill development efforts. As technologies evolve and new demands emerge, it’s crucial to stay informed about market dynamics. The code for the analysis can be found in this repository.
[…] Power BI certification. Given the results of the job market analysis discussed in my most recent article and the fact that I have already wanted to get the Power BI Associate qualification for some time, […]