
The rise of short message communication in recent years has provided individuals and businesses with a fast and interactive way to communicate with their peers and customers. However, this has also led to an increase in the number of spam messages, particularly on publicly available channels. In response to this, we will build a classification model that can identify if a message is spam and allows for an adjustable risk level, ensuring that low-risk messages are immediately displayed while others are moved to a folder for further analysis. We will base our model on this dataset.
To achieve these objectives, this project will follow the CRISP-DM framework, a widely used methodology that provides a structured approach to planning a data science project. We will cover all the necessary steps, including business understanding, data understanding, data preparation, modeling, evaluation, and a suggestion for deployment.
Organizing the Project with CRISP-DM
The first step in the CRISP-DM methodology is the Business Understanding step, which involves understanding the business objectives and requirements of the given task. In this step, we need to define the goals and objectives of the project and identify the stakeholders. This will help us to define the scope of the project and ensure that we deliver a solution that meets the needs of the stakeholders. We will base this project on a fictitious company that has tasked us with building a spam filter for their open channel to enable effective communication with their customers while maintaining message quality.
Business Understanding
For this project, the business objective is to build a spam filter for a new open communication channel that the company wants to install for its products. The aim is to enable fast and interactive feedback for their customers or possible future customers. The spam filter should be able to identify spam messages from short messages and allow for adjustments with respect to the risk of allowing spam to pass. This means that the spam filter should be adjustable via different spam-risk levels, e.g., low-risk (very restrictive) and high-risk (not restrictive). The messages passing the low-risk level are immediately displayed, while the other ones are moved to a folder for further analysis.
The stakeholders in this project are the company, the service team who will be responsible for using the spam filter to filter out spam messages, and the customers, who will be using the open channel to provide feedback or ask questions on the company’s products. It is important to keep in mind the expectations of these stakeholders while developing the spam filter so that we can deliver a solution that is effective and meets the needs of all groups. For the company the emphasis lies on not losing customers from misclassified messages, the service team wants a system that simplifies their daily work and the customers do not want to read too many spam messages, although a lost customer will probably hurt the company more than a spam message entering the channel.
In addition to the primary objectives of the project, it is also important to consider any constraints and assumptions that may impact the project. For example, we could have limitations in terms of the resources available to us, such as the amount of data that we have access to or the computing power required to train and test our models. We may also have to make assumptions about the types of messages that are likely to be classified as spam and adjust our approach accordingly. By considering these constraints and assumptions, we can ensure that we deliver a solution that is realistic and feasible given the resources available to us.
Constraints and Assumptions
Based on the dataset and the resources available, we can identify the following constraints:
- The dataset only includes English messages, so the model will only be able to classify English messages accurately.
- The dataset has a limited number of messages, which may not be representative of all types of messages that the company may receive.
- The analysis and model training will be done on a home desktop PC, which may have limitations in terms of computational power and memory.
and assumptions:
- The messages in the dataset are correctly labeled as ham or spam.
- The dataset is a representative sample of the types of messages that the company may receive.
- The spam filter will be used in a similar context as the dataset, so the model will generalize well to new messages.
Data Understanding
To start the data understanding step, we will first load the dataset and check for any missing values and duplicates. We will use the Pandas library to load the CSV file containing the messages and perform basic exploratory data analysis (EDA).
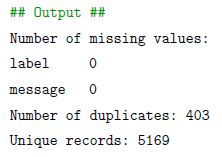
From the above output, we can see that there are no missing values in the dataset, but there are 403 duplicate records. We will remove these duplicate records from the dataset and look at the number of resulting unique records.
![]()
Next, we will explore the distribution of the target variable label with the help of Matplotlib and Seaborn. Additionally, we look at the distribution of the character count of the messages.
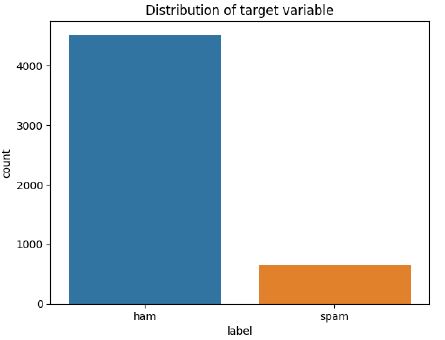
From the first visualization, we can see that the dataset is imbalanced as there are more ham messages than spam messages. This must be accounted for before we train our classifier.
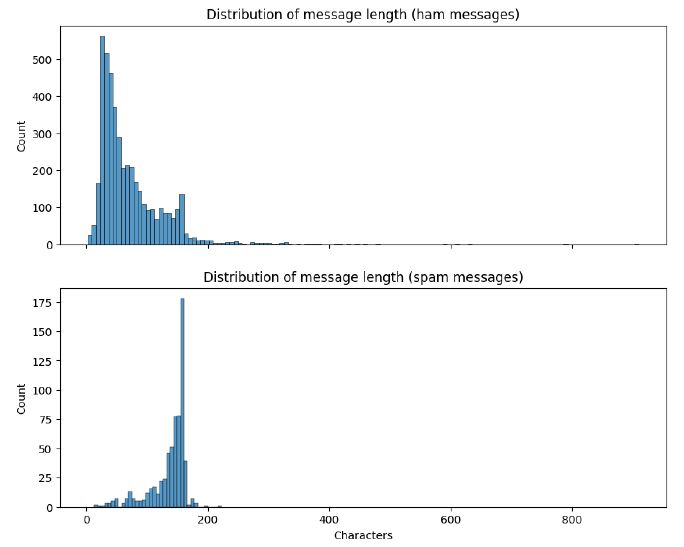
Plotting the distribution of the message lengths, we can observe that spam messages tend to have longer message lengths compared to ham messages. Further looking into the number of digits and special characters reveals that spam messages tend to have more digits.
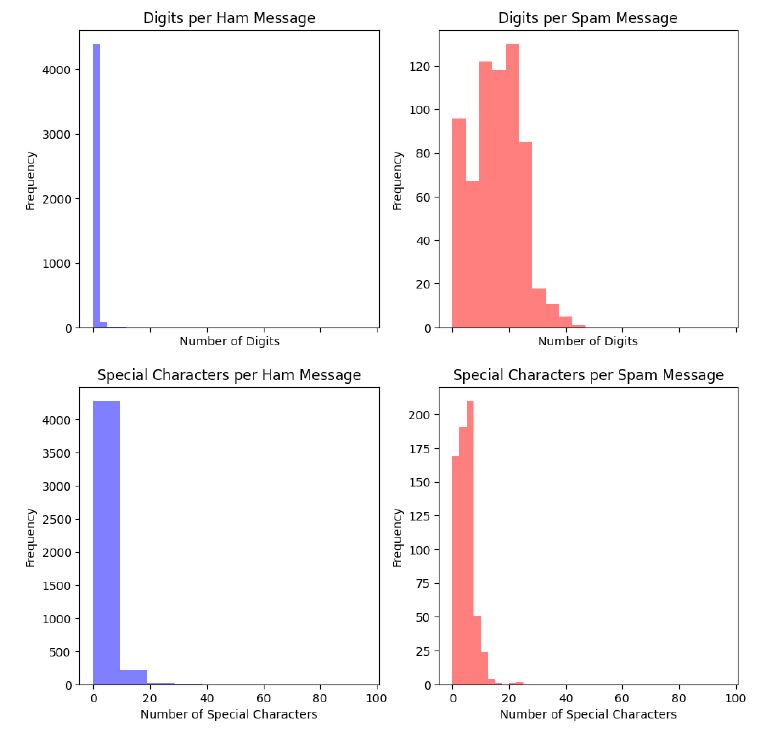
Another interesting feature that we will explore is the number of unique words per message type
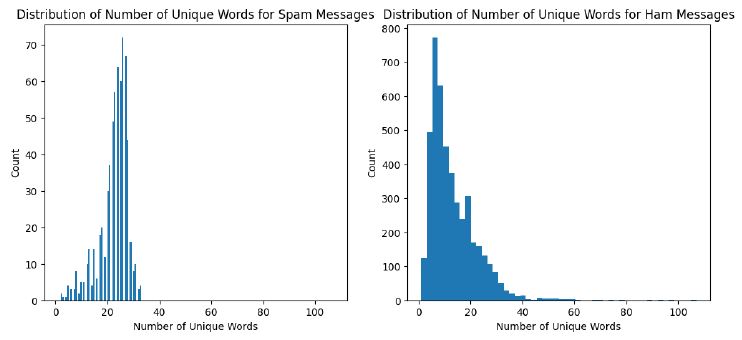
and lastly, we plot word clouds to spot possible differences in vocabulary.

With this, we conclude the EDA and move further on to the data preparation step where we will balance the dataset and choose the most interesting features for training the model. The engineered features for each message will be message lengths, the number of unique words, and a TF-IDF representation of the vocabulary. We will omit the special character distribution as ham and spam messages are very similar in this regard.
Data Preparation
For the next step, we perform data preprocessing and feature engineering on the SMS message dataset. We load the data from the source CSV file, remove duplicates, and create new columns such as message length, number of digits, number of unique words, and a lemmatized version of the messages. The text data is then transformed into a matrix of TF-IDF values using the TfidfVectorizer class of the scikit-learn library. The resulting features are saved along with the trained vectorizer. Additionally, the dataset is balanced by sampling an equal number of ham and spam messages. The target variable is encoded as 0 for ham and 1 for spam and finally, the prepared dataset is saved as a new CSV file.
Model Training
For training, we first load our prepared dataset of messages and split it into training and testing sets. Then we perform a grid search with cross-validation to find the best hyperparameters for our classifier which will be a decision tree. Additionally, the feature importances are retrieved from the trained classifier, and a barplot is created to visualize the top 10 most important features.
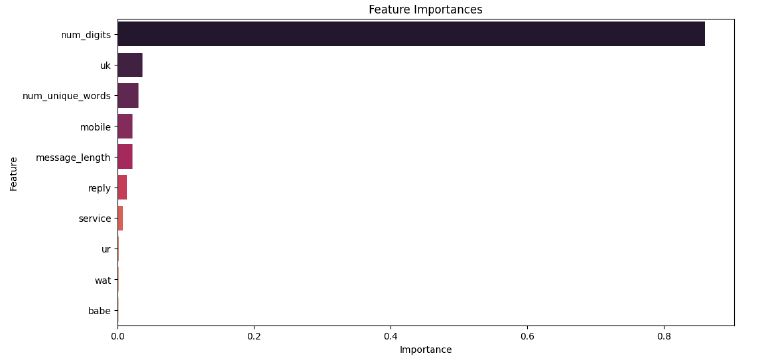
Examining the plot, we can see that the model clearly favors the number of digits in a message as a decision factor. Following we have specific words and our other engineered features.
Error Analysis
After training our model, we will now further analyze the performance. To do this we compute a confusion matrix on our training and test datasets.
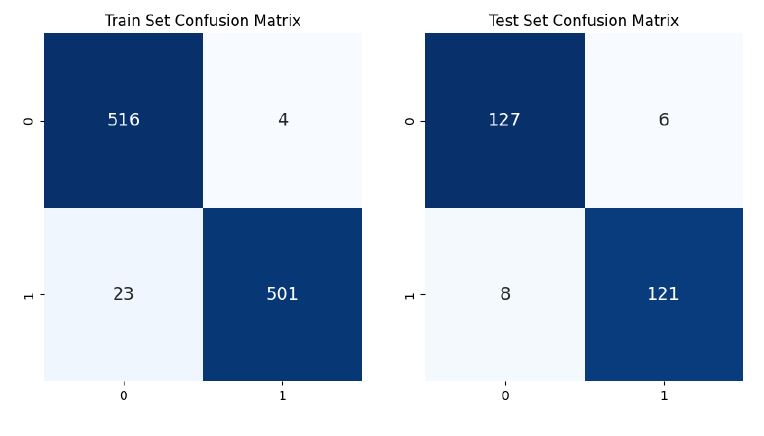
Additionally, we also retrieve accuracy, precision, and recall for each dataset respectively.
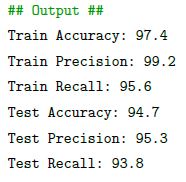
From the metrics, we can conclude that the model performs sufficiently well on our initial dataset. Additionally, we will look into the distribution of misclassified messages.
![]()
With this, we can assume that the model is not particularly biased toward one of the message types. Finally, we will test the model on 10 new messages that were generated with a language model and consist of 5 ham and 5 spam messages. The test results can be examined in the analysis Jupyter Notebook and revealed a reasonable out-of-sample performance and generalization. Although the emphasis of the model on digit counts makes spam messages with no digits and ham messages with more digits hard to classify correctly.
Deployment
To integrate the spam classification model into the service team’s workflow, we could develop a web application using Django. The steps involved in creating and deploying this system would be as follows:
- Set up the Django project structure and configure the necessary settings.
- Design the database schema to store messages and their classifications.
- Set up an API endpoint that receives incoming messages, assuming we have the possibility to control message flow from our communication channels’ backend.
- Implement the web interface using Django’s template system and HTML/CSS.
- Integrate the spam classification model into the project and develop the function to classify messages.
- Implement an adjustable spam level control, allowing the service team to set the level of stringency for classifying messages as spam. The level would be a percentage threshold that can be used for comparison with the probabilities of class membership that the model returns in percentages.
- Deploy the Django application on a cloud platform.
- Conduct thorough testing and quality assurance to ensure functionality and performance.
- Provide documentation and training to guide the service team on using the web application effectively.
- Maintain and improve the system based on feedback and ongoing monitoring.
Conclusion
The objective of this project was to build a classification model capable of identifying spam in short messages. The CRISP-DM methodology was followed, covering business understanding, data understanding, data preparation, modeling, evaluation, and a suggestion for deployment. The dataset’s quality was assessed, and findings were visualized for better comprehension. A decision tree classifier was created, trained, and tested using the provided dataset and additional out-of-sample data. An error analysis was conducted to identify weaknesses in the approach, which would be the reliance on digits for classifying spam. Finally, a proposal was made to integrate the model into the daily work of the service team. The solution would be in the form of a graphical user interface (GUI) based on a Django web application.
In summary, this project successfully developed a classification model for spam identification in short messages. The model returns class membership certainties in percentages which can be further utilized to build logic for adjustable risk levels. Further improvements to the model could be made by gathering additional data or data that is more representative of the use case, i.e. short messages of product feedback or questions. Additionally, there is the possibility of engineering alternative features to reduce reliance on the digit count. The project demonstrates the efficacy of data science methodologies in addressing real-world challenges, offering a valuable solution for the company. The code for this project can be viewed in this GitHub repo.