
In an era where information overload is prevalent, finding efficient ways to extract key insights from vast amounts of data has become crucial. As an aspiring student navigating the sea of academic papers during my time at university, I often found myself spending countless hours reading and analyzing research articles. Motivated by the desire to streamline this process, I embarked on a journey to develop a PDF summarizer using ChatGPT. Additionally, I wanted to leverage ChatGPTs language capabilities to automate the process of generating flashcards from the learning material.
By leveraging the power of OpenAI’s state-of-the-art language model, I aimed to create an automated tool that would help me and others extract essential knowledge from lengthy scholarly texts. The primary objective was to facilitate efficient research and enhance the learning experience for students like myself.
In this article, I will delve into the intricacies of building a PDF summarizer and flashcard generator with ChatGPT. I will discuss the underlying methods and the challenges encountered along the way.
The Portable Document Format
PDF, short for Portable Document Format, has become one of the most widely used file formats for document sharing and distribution. Its popularity is attributed to its ability to preserve the original formatting of a document across various platforms. However, this format presents unique challenges when it comes to extracting information and transforming it into a structured format.
The main hurdle lies in the fact that PDFs store data as a series of graphical elements rather than plain text. While these graphical elements maintain the visual appearance of the document, they pose difficulties for programs aiming to extract meaningful content automatically. Directly accessing and parsing text from a PDF can be complex due to variations in layout, fonts, and non-standard encoding schemes.
Another challenge is that PDFs often contain complex structures such as tables, headings, footnotes, citations, and images. These elements require specialized algorithms and techniques for accurate understanding and extraction. Moreover, despite efforts towards standardized file formats like tagged PDFs (PDF/A), many documents are still produced without such metadata, making it even more challenging to extract relevant information systematically.
To overcome these obstacles and bring the data within PDFs into a structured format, one must employ smart techniques such as optical character recognition (OCR) to convert graphical elements back into text data. Additionally, algorithms need to analyze the layout structure to identify headings, sections, paragraphs, and other textual components accurately, which brings us to the PDF Extract API from Adobe.
PDF Extract API
The PDF Extract API is a cloud-based service to automatically extract content and structural information from PDF documents. It can extract text, tables, and figures from both native and scanned PDFs. When extracting text, the API breaks it down into contextual blocks like paragraphs, headings, lists, and footnotes. It includes font, styling, and formatting information, providing comprehensive output. Tables within the PDF are extracted and parsed, including contents and table formatting for each cell. The API can also extract figures or images from the PDF, saving them as individual PNG files for further use.
We will leverage this API to create a JSON file containing the PDF content and in turn, use this JSON file to create text files that we will feed into ChatGPT for further processing.
The Problem with Summarization
Text summarization is a natural language processing technique aimed at condensing large bodies of text into shorter summaries while still capturing the essential information. With the rise of transformer models like ChatGPT, extractive and abstractive summarization methods have seen significant advancements.
However, when dealing with long-form content such as PDF documents, transformers face challenges due to their limited input length. Transformers typically have a maximum token limit, necessitating the truncation or splitting of longer texts. This approach can lead to the loss of important context and affect the quality of the summary.
To address this limitation and preserve information integrity, we will leverage the headings present in the PDF documents. Headings provide structural organization to the text and can serve as natural breakpoints for splitting the document into smaller sections. By splitting the document based on headings, we can ensure that each section is more coherent and self-contained, resulting in better summarization outcomes.
PDF to JSON
As already explained the first step of our pipeline is the conversion of a raw PDF into a JSON file and the extraction of tables and figures. We will use the paper Attention is All You Need by Vaswani and colleagues which is an important paper about transformer model architecture with over 80 000 citations for testing our approach. If you open the PDF you can see that we have a perfect candidate with a variety of elements such as headings, sub-headings, lists, math formulas, images, footnotes, and tables.
For a detailed explanation of the JSON files structure please refer to the documentation of the API provider. Sending the PDF to the Extract API returns the following files:
From here on out we are confronted with three distinct problems:
- How do we get the information in the JSON file into a format suitable for our use case?
- How do we integrate the tables into the text files?
- How do we handle the figures?
JSON to Chapters
We will start by solving problem one which is the most straightforward to solve. By using the documentation we can iterate through the JSON file and transform the data to our target format, which is a folder of text files each corresponding to a section. A section is thereby everything that is contained between two headings.
The second problem of integrating the tables back into the text files is also relatively easy to solve. When the JSON file indicates a table in its path attribute we read the table into a DataFrame, convert it into a CSV, and instead of saving the data to a file we save it inside our text file. By using | as column separators, ChatGPT is capable of understanding that this should be a table.
The third part on our list is where it gets a bit more interesting. Let’s look at the following two images from the figure folder. Here is the first image
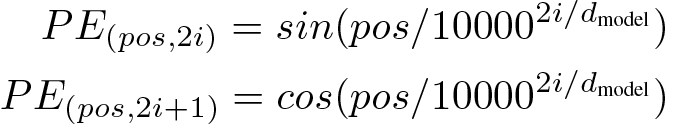
and here is the second image:

Given that this application should also be used for generating flashcards, we need a way to tell apart diagrams and formulas and also to incorporate mathematical formulas into our text. We will omit the diagrams for the time being.
Training a Formula Detection Model
To solve the issue we will train a CNN on a dataset that I compiled from various different sources. We basically need a model that can distinguish between math formulas and everything else that could be included in a PDF. This can range from figures and diagrams to illustrations and images of everything else. The approach to training this model is the same as the one that I have already used for the facial emotion classifier. Given the relatively simple task for the modified VGG19, because the two image categories are relatively distinct, we get an accuracy of around 99% which will have to suffice.
Now we integrate this model into our initial script and every time the JSON file path attribute indicates a Figure, the model is called to predict whether we have a formula or not. Depending on the decision the figure is either skipped or sent to the Mathpix API which returns us a Latex representation of the formula. The Latex code is then included in the text where it can be interpreted by ChatGPT. An example of a text file can be seen below:
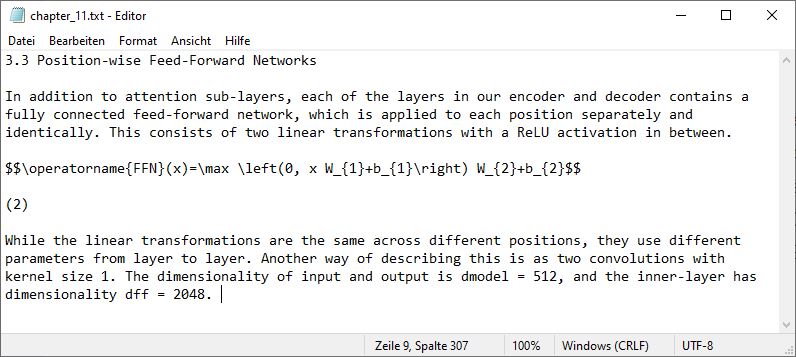
Chapters to Content
With the preprocessing of the PDFs done, we can now move on to the second big part of the pipeline which is the summarization and the creation of flashcards. As I have already mentioned we will use ChatGPT’s capabilities to do this. By using ChatGPT’s API we can improve our results by providing examples of how we want the task done by sending context in the form of a preceding conversation. To convert the information from the raw text files into high-quality summaries and flashcards we will incorporate an intermediate step that chunks the raw text data into blocks of related information. The image below shows the text of chapter eleven in a chunked format.
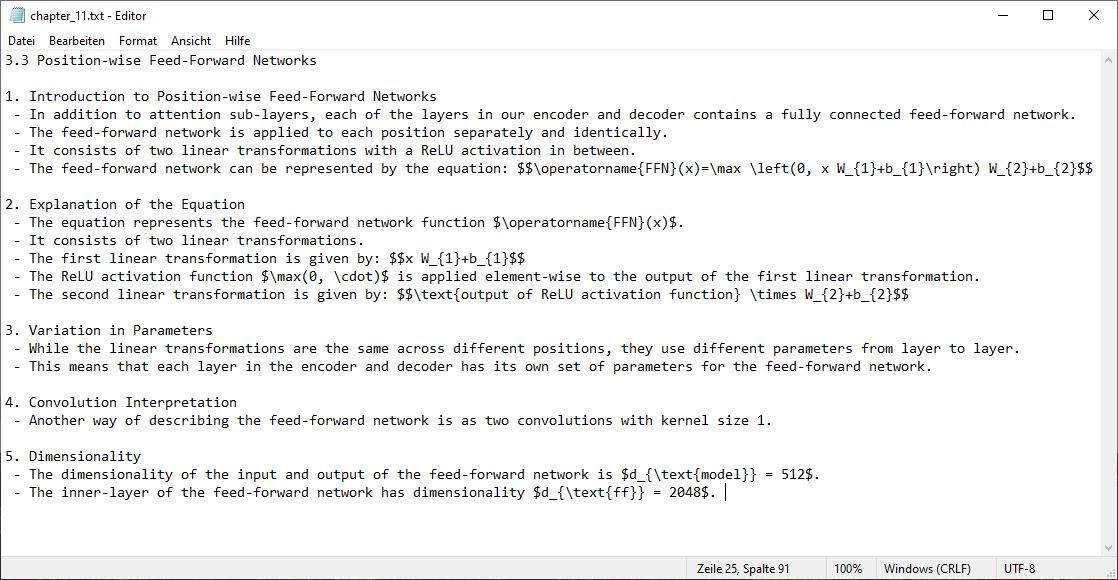
After chunking we then let ChatGPT create a summary

and a list of flashcards:
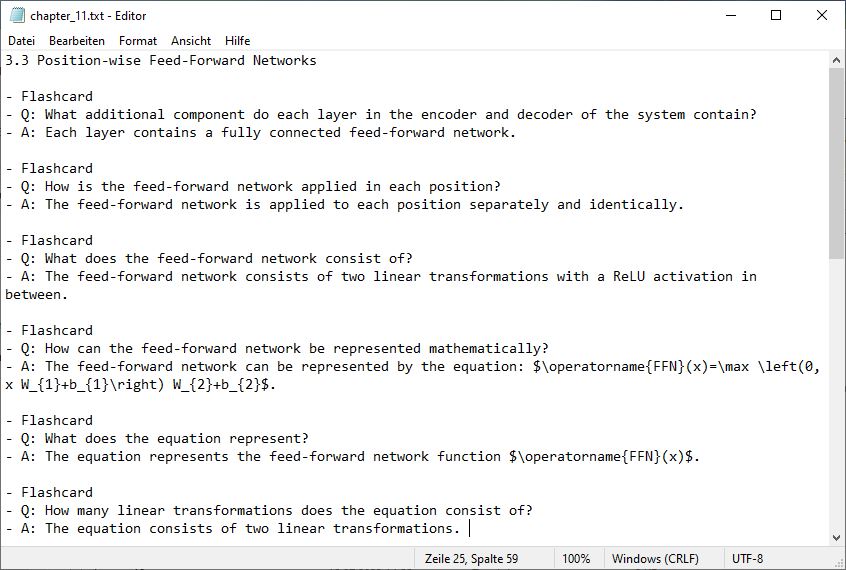
The image does not show all the flashcards that were created. The complete text file can be downloaded here. As you may have noticed, the summary of the section is not really that much shorter than the original section. We will discuss how different lengths of text effects the summaries and the quality of the outputs later on. We also instruct ChatGPT to create flashcards from the summaries which gives us the following list:
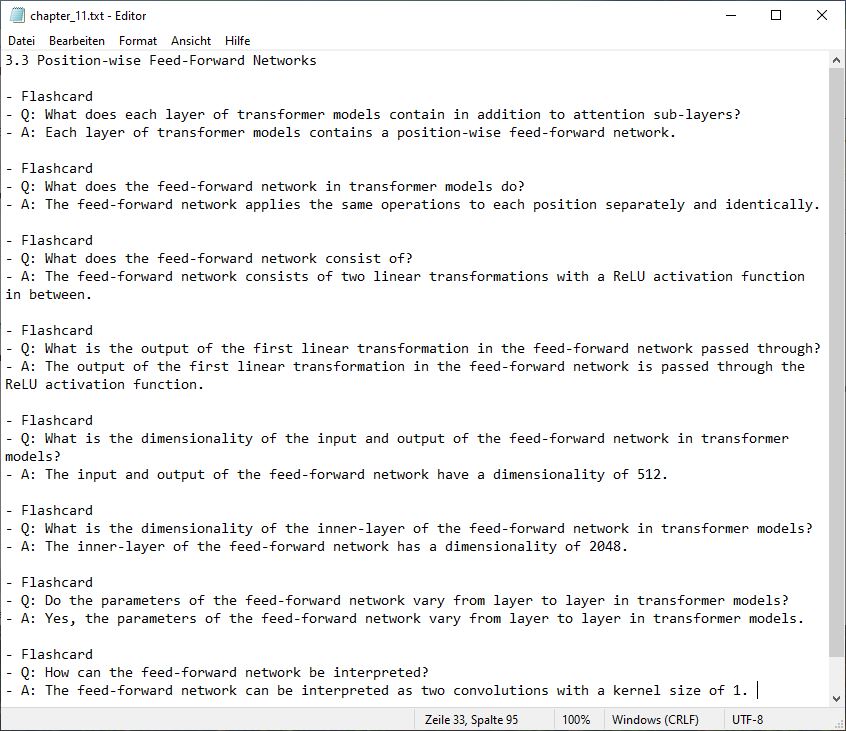
Content to Documents
The last step of the pipeline is to convert the text files into documents that can be further used for studying. We will first look into the CSV files that can be used in flashcard software like Anki. Here we will create two CSV files one for the flashcards from the chunked files and one for the summary flashcards.
In addition to the question and answer that makes up a flashcard, we also include the source (document name), the section heading, and the two combined inside a tags column, which is a sorting mechanism used by Anki. Given the correct settings inside Anki, we can import the 238 flashcards from the chunked text and the 113 flashcards from the summaries. An example of how this looks inside Anki in its final form can be seen below:

The second type of document which we will create is two Word documents that contain the chunked sections and the summarized sections.
Discussion of the Results
Does our pipeline here perform flawlessly? No. Is it enough so that I could save a lot of time on tedious work by hand? Yes, absolutely.
Summaries
First of all, let’s talk about the rate of shrinkage that a document undergoes. The size of the resulting summary is dependent on how large the individual sections are and I think the GPT model handles this very well because larger sections get condensed more, and smaller sections that contain less information to begin with, do not get summarized too much. As you can see from our example, we have around 30% percent shrinkage of the original text, if we only consider the actual text as graphics, references and the abstract have been removed.
On the other hand, I tested this pipeline on my written university lectures that have several hundred pages and here I often got a reduction of around 50% or more, of course depending on the structure of the document. So a rule of thumb is that a lot of text without much headings and graphics gets condensed more and a document with sparse text gets condensed less.
The summaries that this pipeline generates can also be used as input for more summaries and solves the problem of too large input contexts, of course only if the original document is not too large to begin with. Here is an example of a one-page summary based on our five-page summary, that could be used for example to speed up a literature review :

Another idea would be to build a recursive summarizer where we first summarize sub-sections and then summarize these summaries into section-level summaries. Similar like OpenAI did in their case study. Regarding the quality of the summary I can of course only give you my subjective opinion as there is no standardized process to measure the quality of a summary. First I would like to explain how I use summaries in my overall approach to studying for a subject. The summary is used to get a first understanding of how the topics of a subject relate to each other and effectively reduces the time to do so by omitting detailed information.
So in essence you can focus on building a higher-level overview of how topics relate and care for the details of a specific topic later on. Given that I studied successfully for several exams with this approach I am personally satisfied with the quality of the summaries and the time that the automated generation saved me.
Flashcards
Next, we will look into the flashcards. As you may have noticed, the flashcards are very granular which means that practically every bit of information is transformed into a question-and-answer format. The idea here is to curate the flashcards during the revision process, so you have built an understanding of what the learning material is about with the summaries, then studied the material in detail with the chunked and original text and finally revise it with the flashcards.
During this revision process, you can then remove or rephrase sub-optimal cards and also check gaps in your existing knowledge. Additionally, you can evaluate the cards during studying which also can be considered a form of interleaved retrieval practice and results in better learning outcomes at least in my case. And last but not least the automated flashcard generation reduced the time it took to study for an exam, as I found curating the cards is faster than writing them from scratch. Of course, you can also just study the summary cards and call it a day.
Conclusion
In conclusion, the use of the PDF summarization pipeline built with ChatGPT has proven to be a game-changer in reducing study time and eliminating tedious handwriting work for me. The possibility for models like ChatGPT to act as a multitask-learner with minimal input is really fascinating and allows for a vast amount of use cases like this one. It is important to note that I use the GPT-3.5 model although GPT-4 is already available because the price per token demands it. A larger document with 100-200 pages costs around 2-3 $ at this time with the GPT-3.5 model and would cost 10 times as much with GPT-4.
I already did tests with GPT-4 but the capabilities in regards to the transformation of text are not that much different between the two models to justify the costs. This also coincides with what OpenAI reported about the difference between the two models. Given the rapid advancements of this technology and the large number of tasks that can be solved with large-language models, I am looking forward to years of interesting application development. This time there will be no code on GitHub, if my coding skills interest you please refer to my other works.
[…] follows the same logic as the PDF conversion pipeline that was used for the ChatGPT flashcard generator and document summarizer, where the headings are used to split up a larger file into chapters. This semantically correct […]